위경도 데이터 s3 cost 90% 줄이기 (w. data storage format)
Motivation
경로 서비스 backend를 설계/구축하면서 추천 과정을 tracking 하기위해 주요한 의사결정 데이터들을 로깅하였고 장거리 추천의 경우 한번의 추천을 받는 과정에서 수천개의 위경도 데이터가 쌓였습니다.
유저수 증가 및 MLOPS의 확장에 따라 위경도 데이터가 가파르게 증가하여 storage volumn을 줄이는 방법을 고민하게 되었고, compression format 및 데이터 도메인 특성을 이용하여 90% 이상 storage cost를 줄인 방법을 공유하고자 합니다.
Contents
Compression format
table metadata로 aws glue data catalog를 이용하고 있고, parquet 내부의 compression format으로 gzip, snappy, zstd, lzo들을 지원하고 있습니다.
일반적으로 compression format을 선택할때는 compression ratio와 read/write speed 간의 trade off 가 존재하기 때문에 use-case에 맞는 option을 선택하여야 합니다. snappy 는 compression ratio 보다는 read / write speed가 빠르기 때문에 자주 조회되는 hot data에 많이 이용되고, gzip은 write시 많은 리소스를 사용하여 snappy보다 더 높은 compression ratio를 가지고 있는 만큼 saving cost가 중요한 cold data에 이용됩니다. 또한 zstd 는 상당히 높은 compression ratio를 가지면서도 write/read시 준수한 속도를 유지하기 때문에 범용적으로 많이 사용됩니다.
추천과정에서 발생한 위경도 데이터 특성에 맞게 관리/저장 필요성 느꼈기에 compression format별 file size를 비교해보았습니다.
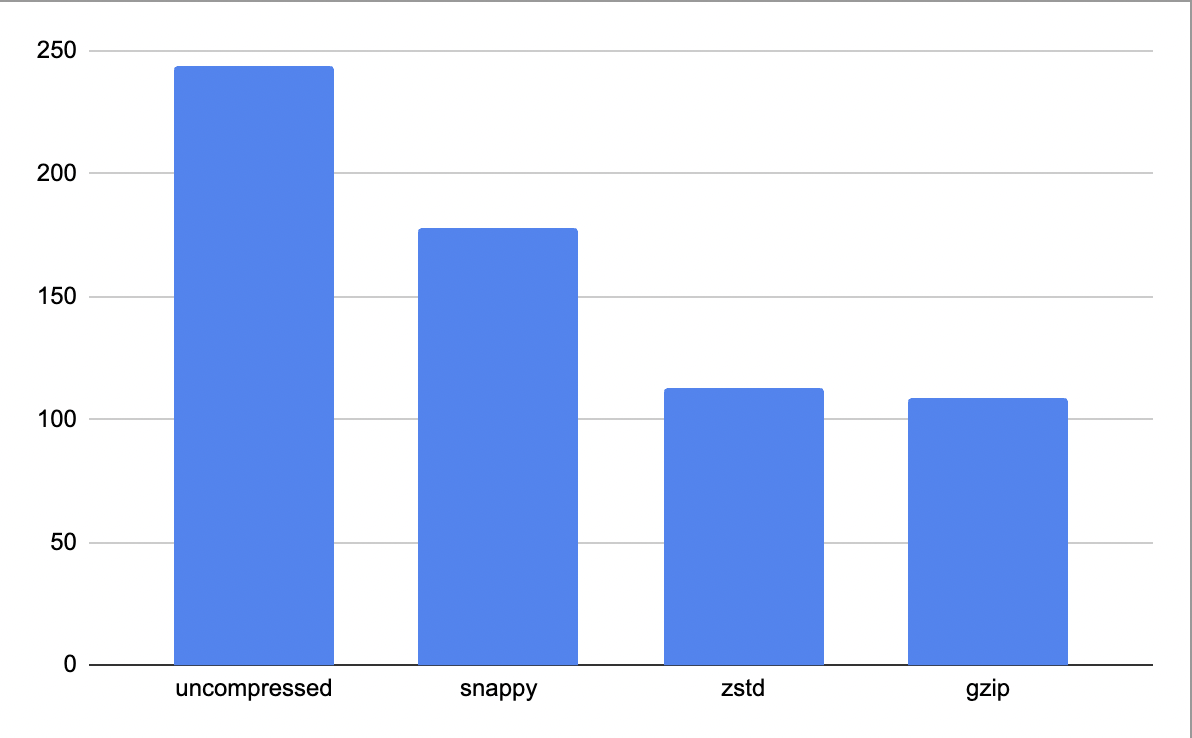
compression을 적용만 해도 uncompressed 된 table 보다 50%이상 size가 줄어드는것을 볼수 있습니다. hot data용인 snappy compression보다는 zstd와 gzip이 size가 더 작았고, 제일 압축이 많이 된compression format은 cold data용 compression format인 gzip 이었고 원본데이터에 비해 55%정도 줄어들었습니다.
Column Reordering
경로 위치 데이터에서 발견한 또다른 특성은, 동일한/유사한 값이 많이 존재한다는것이었습니다. 예를들어 A란 유저와 B란 유저가 서울 지역에서 동쪽 관광지(ex: 강원도) 경로를 추천받았을 경우, 대한민국의 고속도로 특성상 공통된 고속도로 (하남IC →춘천IC)를 지나야하고, 이경우 A와 B유저의 위경도 데이터에 구간별로 동일/유사한 point들이 많이 분포하게 됩니다. 더욱이 장거리일수록 고속도로 또는 자동차전용도로의 비율이 높아지기 때문에 유사한 비율이 올라갑니다.
이와같이 데이터 유사도가 높을때 유사한 위경도값끼리 묶고 compression을 진행한다면 압축률이 더 올라가고, compression format에 따라서도 세부적인 압축률이 달라집니다. snappy, gzip과 zstd compression format에 유사도를 높이기 위한 sorting까지 적용하였을때 size reduction을 같이 보시죠.
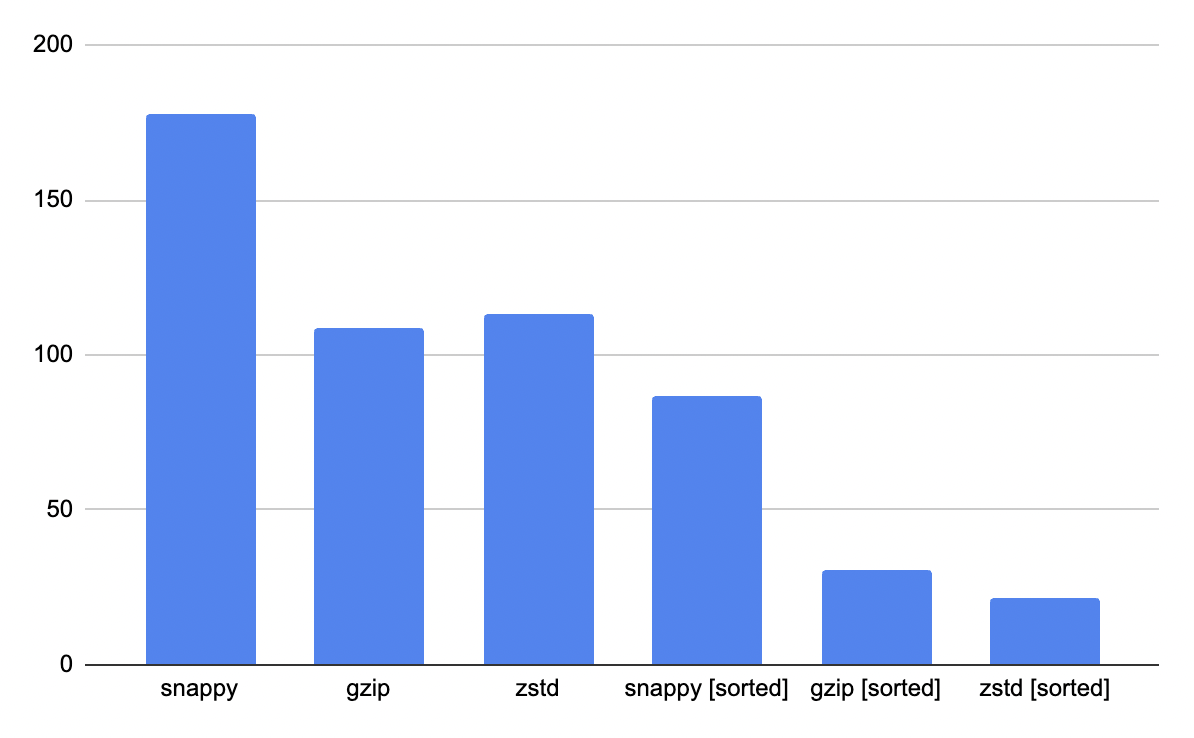
모든 compression format에 대해서 sorting이후 압축 진행시 compression ratio가 증가하는것을 보실수 있는데요, 이는 같거나 유사한 데이터별로 sorting해서 저장할경우 parquet의 encoding 최소 단위인 page내에서 데이터의 유사도가 증가하며 압축 비율이 더 높아지기 때문입니다.
또한 compression format별로도 sorting + 압축에 따른 감소효과가 달랐는데요, snappy는 51.2%의 size 감소가 있었던 반면 gzip은 72%, 그리고 zstd는 80.9%의 compression 효과를 보이며 zstd가 가장 높은 압축률을 보여주었습니다. zstd의 경우 column내에서 반복해서 일어나는 값일경우 해당 값의 시작과 끝 지점의 index로 encoding이 진행되기 때문에 위경도의 복잡한 소숫점 값들을 효과적으로 줄일수 있습니다.
Conclusion
지금까지 compression format 및 데이터 특성을 고려하여 위경도 로그 데이터의 압축률을 크게 개선한 경험을 공유하였습니다.
MLOPS를 진행하면 여러 형태의 로그가 쌓이고, 그중 위의 위경도 데이터처럼 saving cost를 줄이는게 중요한 data가 있을텐데요, 데이터의 use-case에 맞는 compression encoding과 데이터 특성을 고려한 압축을 진행한다면 상당한 수준의 compression ratio 향상을 기대해볼수 있을것 같습니다.
Reference
https://www.uber.com/en-IE/blog/cost-efficiency-big-data/
https://medium.com/insiderengineering/apache-iceberg-reduced-our-amazon-s3-cost-by-90-997cde5ce931