[Data storage format] - Parquet vs ORC 비교하기
Motivation
big data storage file format에는 OLAP 특성에 맞게 columnar file format이 많이 쓰이는데요, columnar file format을 선택할때 engine과의 호환성, use-case 들이 선택의 요소들이 됩니다. 최근에는 hive ecosystem 만 지원되는 ORC가 아닌 spark와 같은 여러 data framework와의 호환이 가능한 Parquet이 주로 쓰이고 있습니다.
또한 Parquet과 ORC의 use-case로 Parquet은 write-once-read-many에 적합하고 ORC는 write-heavy 에 적합하다는 차이점이 있습니다. 구체적으로 왜 use-case가 달라지는지, 각 format의 어떤 구조 특징때문에 차이가 나는지 정리해보고자 합니다.
Content
ORC
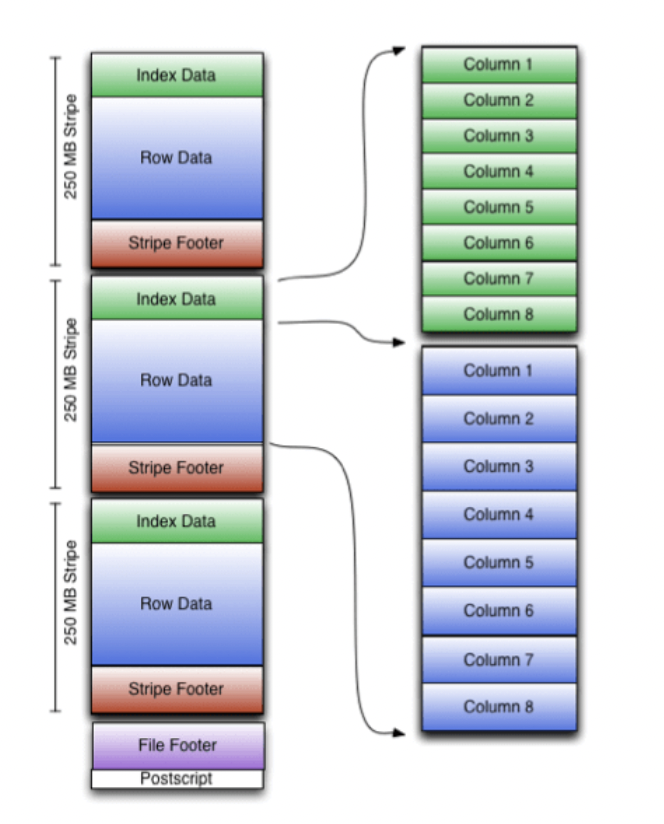
ORC file은 크게 postscript, file footer 그리고 row data groups(stripes)로 이루어져 있습니다. postscript는 compression 관련 정보가 들어 있고, file footer는 stripe list, row 갯수, 그리고 파일단위의 column-level aggregate feature 들을 가지고 있습니다.
실제 데이터가 저장된 stripe structure은 index data, row data, stipe footer로 구성되어 있습니다. 구성요소들중 index data가 중요한데요,
index data에는 stripe내 column의 meta정보 + row position들을 가지고 있습니다. ORC의 이 index data는 실제 query를 응답하는데 사용되지는 않지만 stripe selection에 주요하게 사용됩니다. index를 활용한 predicate filtering을 통해 row_data를 읽지 않고도 O(n)의 disk I/O를 통해 stripes(row group) reading을 skip 여부를 판단할수 있습니다.
Parquet
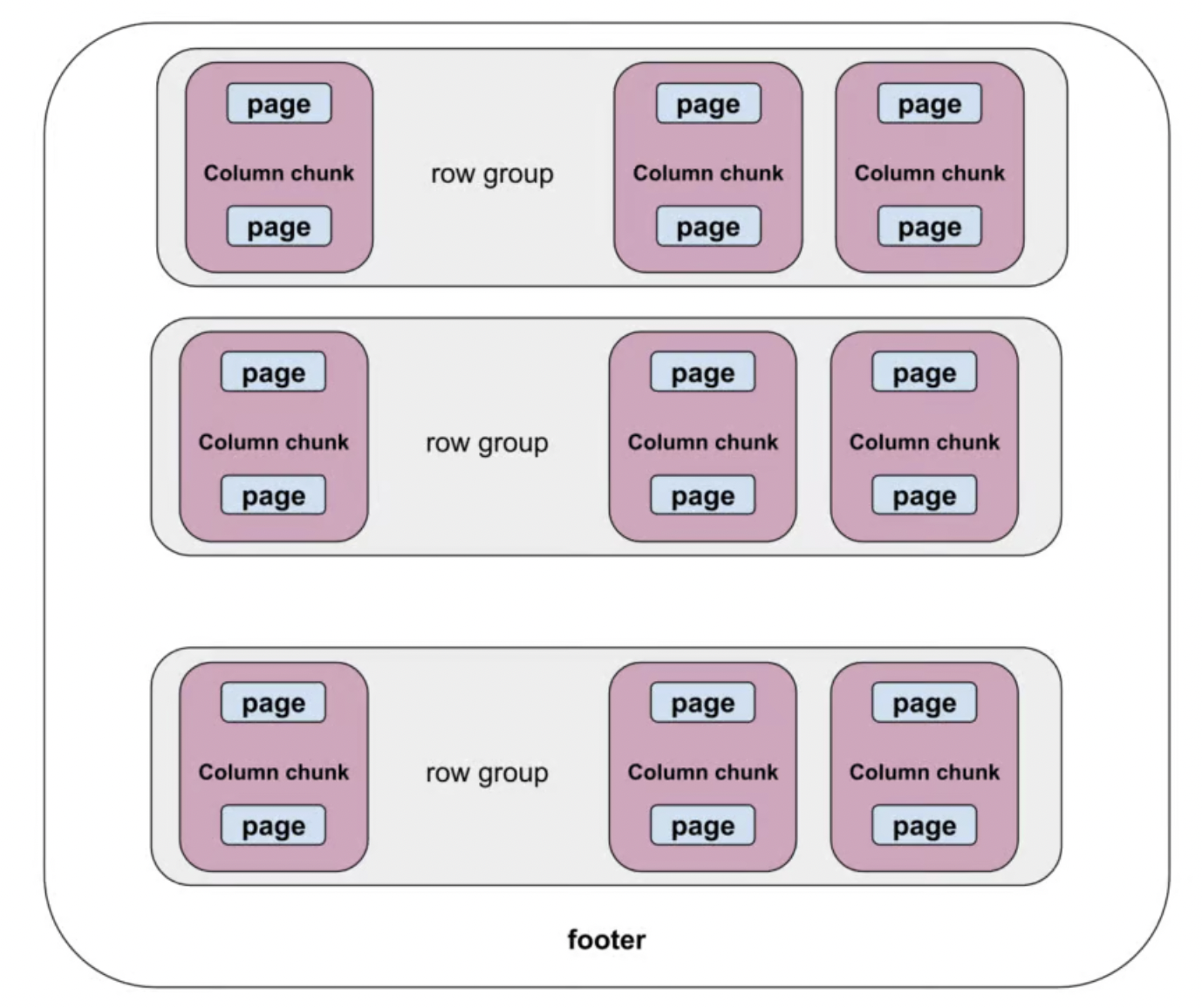
parquet file format은 크게 row group과 footer(metadata)로 이루어져 있습니다.
첫번째 구성요소인 row group 은 각 column 정보를 담고있는 column chunk들로 이루어져 있고, column chunk는 encoding과 compression이 적용된 page들로 이루어져 있습니다. IO 병렬처리시 최소단위는 column chunk이지만 encoding/compression의 최소단위는 page 입니다.
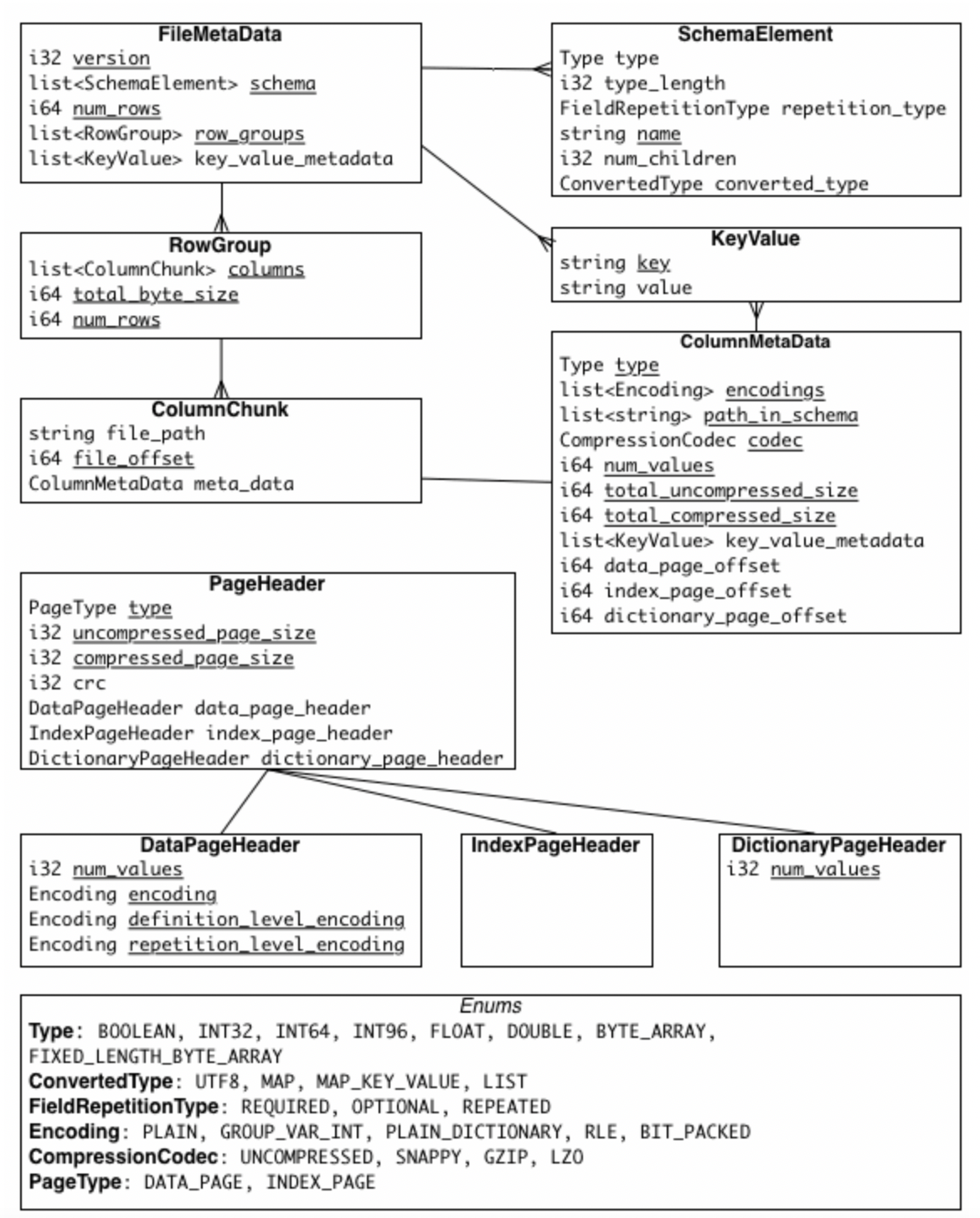
두번째 구성요소인 footer(이하 metadata)는 크게 file metada, column(chunk) metadata, page header metadata로 이루어져 있습니다. 이중 filemetadata는 list<’Rowgroup’> 을 통해 row group의 metadata를 관리하고, row group 내부에는 각 column chunk 정보를 list<’ColumnChunk’>를 통해 관리하고 있습니다.
이렇듯 parquet의 metdata는 row_group data와 분리되어 있으며 row_group / column chunk 단위로 정보를 분리해서 관리하고 있습니다. 이로 인한 parquet의 특징은 무엇일까요?
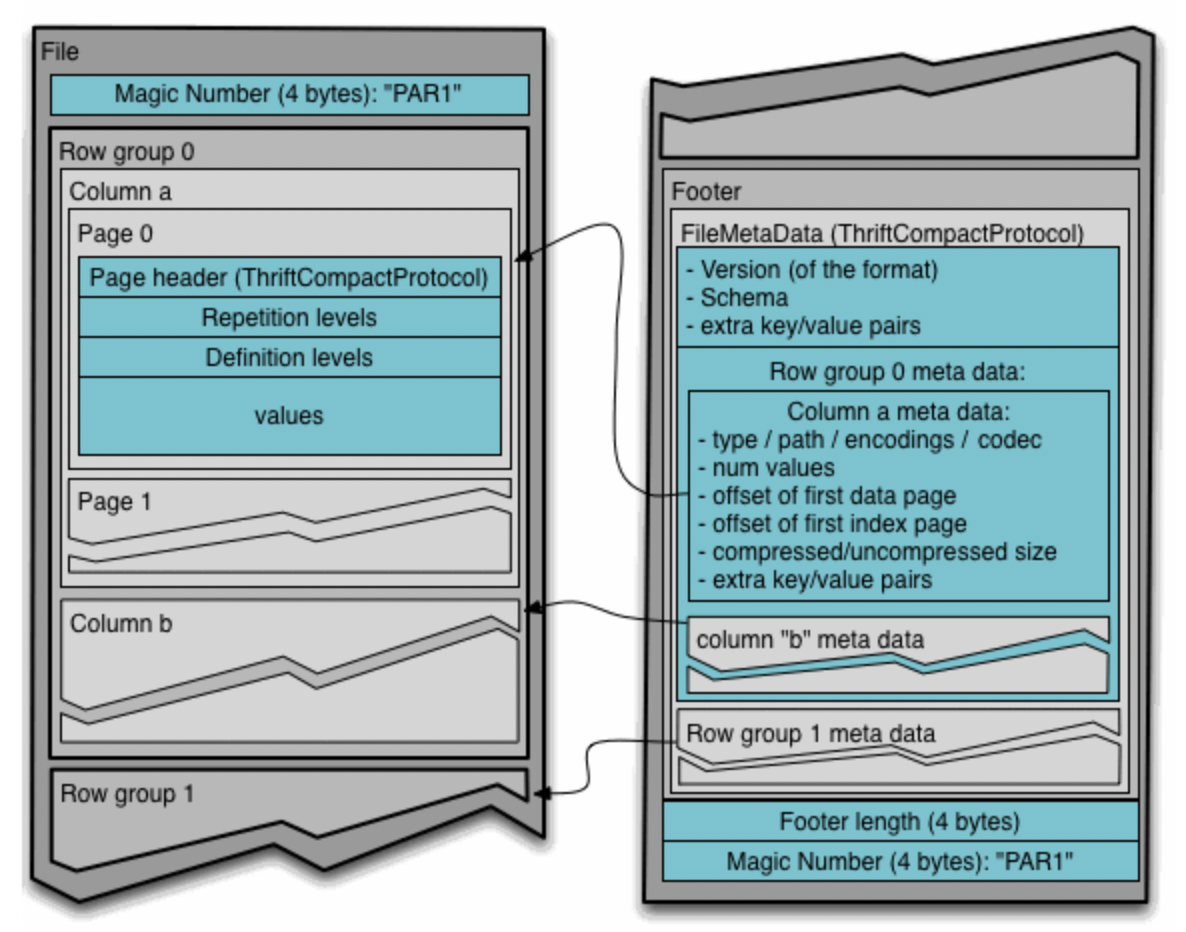
parquet은 metadata와 data를 분리하기 위해 디자인 되었으며,
reader는 row_group 을 조회하기 전 metadata를 먼저 읽음으로써 필요한 row_group / column chunk 들을 data 조회 없이 filtering 할수 있게 되었고 read operation시 disk I/O를 O(1) 으로 획기적으로 줄일수 있게 되었습니다. (이점이 ORC와 가장 큰 차이점이라고 생각합니다.)
Conclusion
Parquet data와 metadata가 분리되어 있고, metadata 한번 scan(O(1))만을 통해 필요한 row_group / column chunk들을 파악할수 있습니다. 이러한 metadata 분리를 통해서 write시에는 추가 시간이 들수 있지만, read시 I/O를 줄일수 있는, write-once-read-many operation에 적합한 format인 특징이 있습니다.
ORC는 data와 metdata(index)가 분리되어 있지 않습니다. 물론 read시 row-group별 index data를 이용한 predicate filtering을 통해 row-group filtering 역할을 어느정도 수행할순 있지만, 각 file의 stripe 별로 index data를 읽어 들어야 합니다.(O(n)). read시 disk I/O가 많은 특성으로 인해 read-many 보다는 metadata file을 별도로 관리할 필요가 없다는 장점때문에 wirte-many operation에 적합한 특징이 있습니다.
Reference
Parquet, ORC, and Avro: The File Format Fundamentals of Big Data